
When I pitched the idea to my professor about TrustNet, I thought the hardest part would be training a model that could discern fake news from real news.
Oh, but I was so wrong.
The real challenge of this project wasn’t getting high accuracy, but answering a much harder question:
How do you build a system people can actually trust?
TrustNet became my capstone project, but it also became the project that fundamentally changed how I think about machine learning. Through this project, I learned that this projectcould be more than just a prediction engine, but a system that people would interact wit,h and I had to ensure to strip all the bias and uncertainty the system could get from its data source.
Fake News Was Never Just a Classification Problem
My preliminary research confirmed my assumption that misinformation spreads quickly, and often convincingly, especially in the social media medium. Many machine learning projects approach fake news as a binary task: fake or real. That framing works well for benchmarks, but it honestly felt incomplete to me.
If a model says an article is “fake,” what is a user supposed to do with that information?
- Trust it blindly?
- Dismiss it entirely?
- Assume the model understands what “truth” is?
These questions became the motivation behind my TrustNet project. Instead of focusing solely on accuracy or F1-score, I wanted to explore a trust-aware NLP, a system that could take into account signals, context, and reasoning, not just labels.
What TrustNetActually Does
FakeNet is an end-to-end NLP system that combines three ideas into a single workflow:
1. Fake News Detection
Given a full article, the system predicts whether it is likely real or fake and shows probability scores rather than a single definitive answer.
2. Stance Detection
Instead of analyzing text in isolation, FakeNet evaluates how an article relates to a claim. Does it agree, disagree, discuss, or remain unrelated? This adds nuance that binary classification completely misses.
3. Explainability
Every prediction can be inspected. Users can see which parts of the text influenced the model’s decision, instead of treating the output as a black box.
The goal was never to declare “truth.” It was to encourage informed skepticism.
How the Project Evolved (And Why That Matters)
One of the most important design decisions I made was to build this system incrementally. I didn’t jump straight into transformers like BERT. I started with classical supervised machine learning, moved through recurrent neural networks, and only then transitioned to transformer-based models. This progression mattered because it forced me to understand why each step was necessary instead of defaulting to the most powerful tool.
Along the way, I worked with over 60,000 deduplicated news articles from multiple misinformation datasets and the FNC-1 dataset for stance detection. Cleaning, standardizing, and validating those datasets took far longer than training any model and taught me how good data matters.
When Things Started to Feel… Suspicious
At one point, my classical models started performing too well. Logistic regression and TF-IDF-based models were achieving surprisingly high accuracy on stance detection, far better than what is usually reported for that dataset. Sirens went off instantly. I’ve heard my professors say this is almost always a red flag, and my own experiences were telling me this could not be possible.
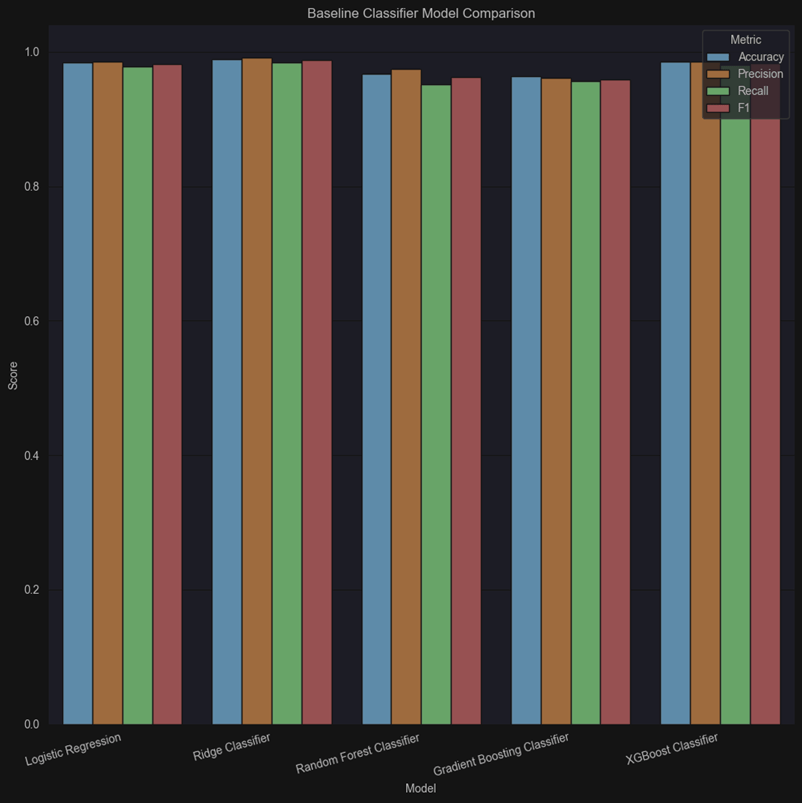
I started asking questions:
- Was there hidden data leakage?
- Were lexical shortcuts doing most of the work?
- Had preprocessing unintentionally made the task easier than it should be?
That moment was important. It reinforced the idea that strong metrics don’t automatically mean strong understanding. If anything, unexpectedly good results can be a reason to slow down and investigate.
Transformers Solved Some Problems… and then Exposed Others
When I fine-tuned transformer models, performance improved dramatically for both fake news detection and stance detection. More importantly, the models handled context far better than anything I had built before.
But transformers introduced a new problem: opacity. A highly accurate model that can’t explain itself is still a liability, especially in domains involving public trust and misinformation. That’s where explainability stopped being a “nice-to-have” and became essential.
Explainability Changed How I Evaluated Models

Early on, I knew I would have to use SHAP-based explanations, as I already had some experience with this library from my summer research. While powerful, they were slow and unstable for transformer architectures. Eventually, I switched to a transformer-specific explainability approach that produced token-level attributions directly from the model.
That change reshaped how I evaluated everything.
Explanations revealed:
- Overreliance on emotionally charged words
- Sensitivity to headlines over article bodies
- Ambiguous correlations that accuracy alone hid
Explainability wasn’t just for users; it became one of my primary debugging tools. If a model’s reasoning didn’t align with human intuition, I treated that as a failure, even if metrics looked great.
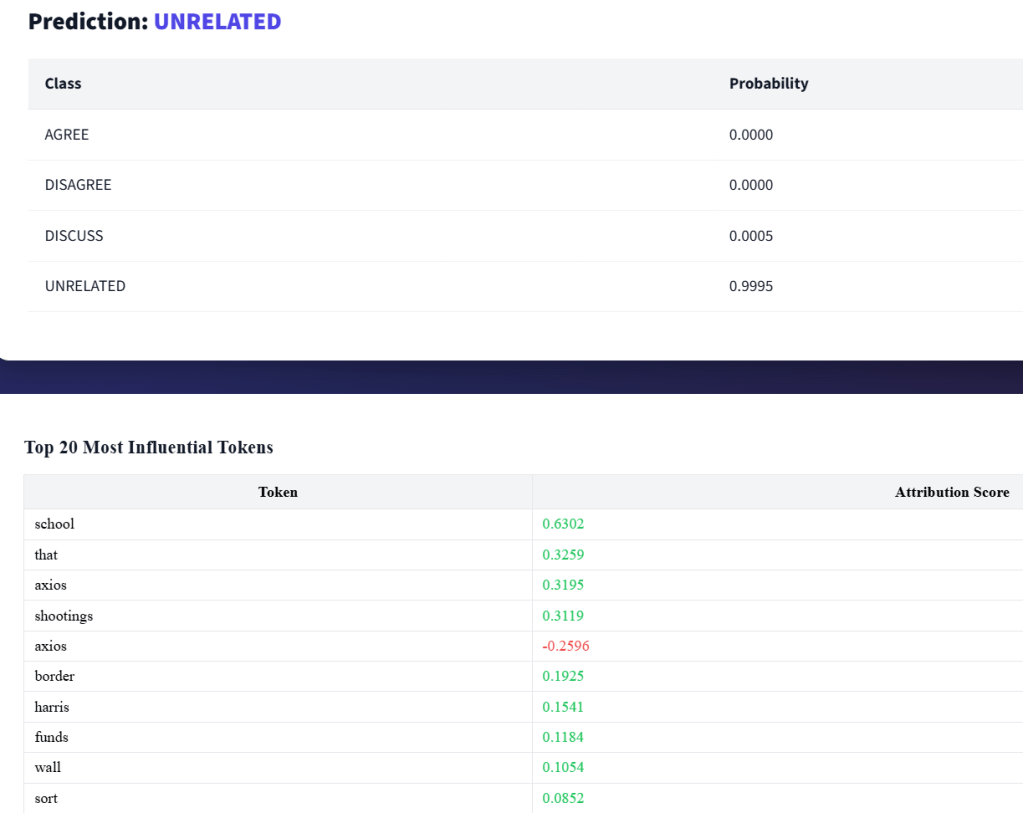
What I Learned
Technical Lessons
- NLP models are extremely sensitive to dataset artifacts.
- Long-form text requires design compromises, not just bigger models.
- Explainability tools are essential for validation, not just presentation.
Research Lessons
- Defining the right question matters more than optimizing metrics.
- Failure cases are often more informative than success stories.
- Trust is a system-level property, not a model feature.
TrustNet forced me to think beyond “Can I predict this?” and toward “Should I trust this prediction, if so, why?”
What Next?
If I were to continue this project, I’d focus on:
- Cross-domain generalization to unseen sources
- Temporal analysis of how narratives evolve
- Network-level signals, such as coordination and bots
- Human-in-the-loop evaluation for interpretability
These directions push the project from a capstone into genuine research territory.
Why This Project Changed My Direction
TrustNet is the project that convinced me I want to pursue research in trustworthy machine learning and NLP. It taught me that high performance is not the same as high reliability, and that models don’t exist in isolation as they influence how people interpret information.
This project didn’t just teach me how to build better models.
It taught me how to ask better questions.
And that, more than any metric, is what I’m taking with me into graduate study and beyond.
Project link: https://github.com/Barderus/TrustNet

Leave a comment