
This project started with a simple question:
“Is there a relationship between a Pokémon’s type and its base stats?”
That’s how most data projects begin: with curiosity and a CSV. I loaded the full Pokédex dataset expecting to run some basic distributions: maybe compare average Attack across types, or see if Dragon-types really are as overpowered as they feel. And I did do some of that. But somewhere along the way, the analysis took a sharp turn.
It became a team recommender.
Data Exploration: Type vs Stats
My first step was simple EDA. I grouped Pokémon by their primary type and calculated average base stats:

This gave me an immediate sense of how types stack up. Unsurprisingly:
- Dragon and Psychic types lead in Special Attack
- Rock and Steel types dominate in Defense
- Electric and Flying types rank high in Speed
From there, I wondered: Could we actually predict a Pokémon’s type just by its stats?
Predicting Type from Stats
I built a basic multiclass classification model using scikit-learn to predict Type 1 from the six base stats.

Summary
- Objective: Predict a Pokémon’s primary type (
Type 1) from its stats. - Focused on the top 11 most common types, grouped the rest as “Other”.
- Used stratified train/test splits to address class imbalance.
- Tried Random Forest, XGBoost, Gradient Boosting, and Stacking Classifier.
- Best accuracy: ~30% with Stacking Classifier.
Model Performance Comparison
| Model | Accuracy | Notes |
|---|---|---|
| Random Forest | ~0.26 | Better than baseline, struggles on rare types |
| XGBoost (tuned) | ~0.27 | Balanced tradeoff, better on “Normal”/”Other” |
| Gradient Boosting | ~0.29 | Competitive, slight improvement |
| Stacking Classifier | 0.30 | Best so far, improves recall for some types |
Challenges
- Many types share similar stat profiles (e.g., Water vs. Normal).
- Underrepresented types (e.g., Ground, Dragon, Rock) make it hard to boost recall.
- Stats alone miss critical context like abilities, moves, and dual types.
- The “Other” category introduced ambiguity by mixing multiple less-common types.
The result? About 30% accuracy. Even with more complex models like XGBoost and stacking, the ceiling didn’t move much.
So I pivoted. What could we predict?
Predicting Legendary Status
I reframed the problem to a binary classification: can we predict whether a Pokémon is Legendary based purely on its base stats?
This problem proved much more promising. The class imbalance (Legendary Pokémon are rare) made recall especially important. I tested several models: Random Forest, XGBoost (both tuned and default), and finally, a Stacking Classifier, and used scale_pos_weight to help with imbalance, where applicable.

Here’s a detailed comparison of the model performances:
| Model | Accuracy | Precision (Legendary) | Recall (Legendary) | F1-score (Legendary) |
|---|---|---|---|---|
| Random Forest (default) | 96.25% | 0.75 | 0.60 | 0.67 |
| Random Forest (tuned) | 94.00% | 0.50 | 0.70 | 0.58 |
| XGBoost (default) | 95.00% | 0.57 | 0.80 | 0.67 |
| XGBoost (tuned) | 93.00% | 0.47 | 0.70 | 0.56 |
| StackingClassifier | 94.00% | 0.50 | 0.90 | 0.64 |
Model Insights
- Best Recall: The StackingClassifier achieved 90% recall on Legendary Pokémon, the highest of all models, while maintaining high overall accuracy.
- Best F1-score: XGBoost (default) slightly edges out the rest at 0.67, but StackingClassifier comes close with 0.64 and stronger recall.
- Most Balanced Model: The StackingClassifier offers the best trade-off between recall and generalization, making it the recommended model for deployment or interpretation.
Evolving into a Recommender System
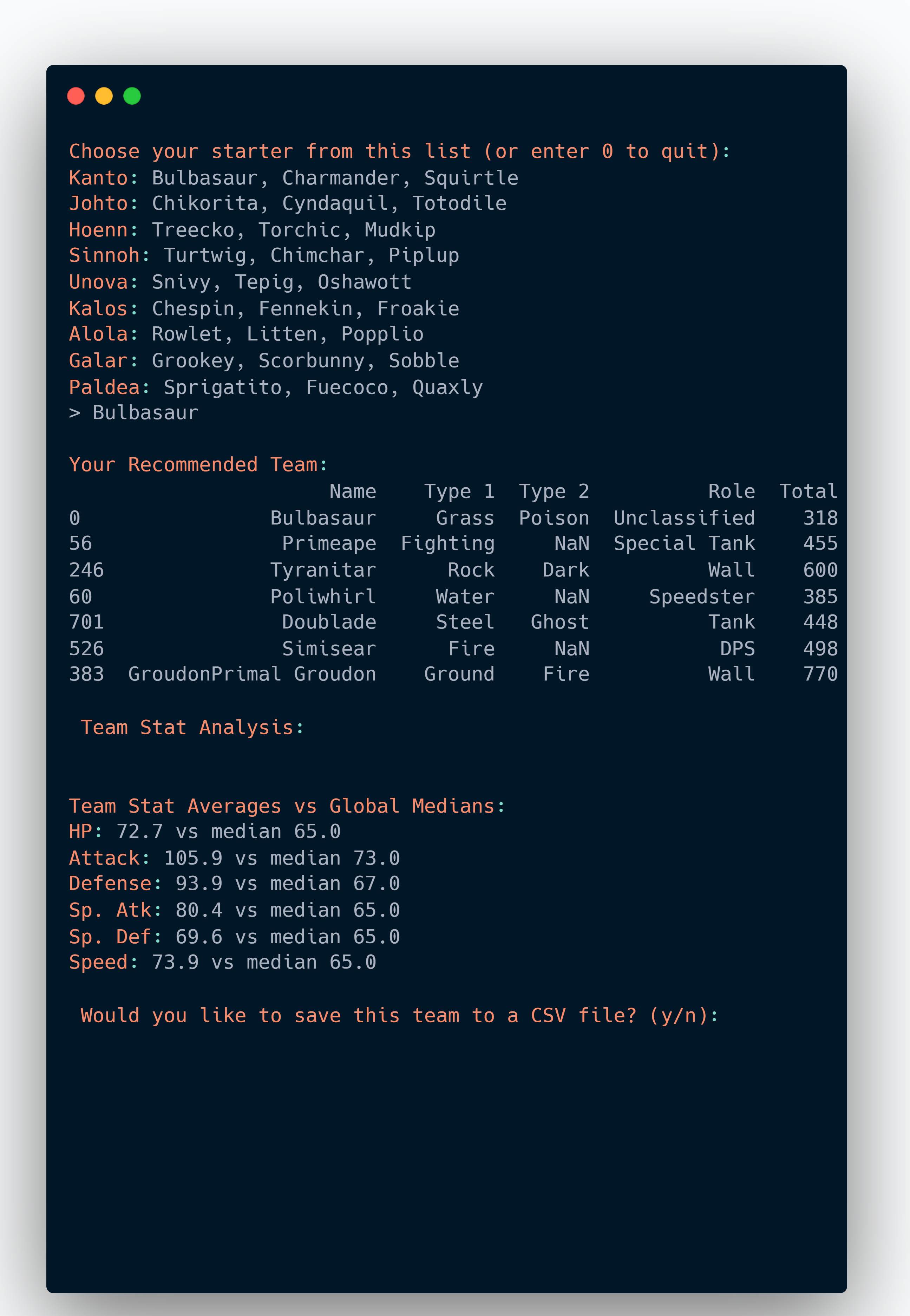
That’s when I had the idea to build a Pokémon Team Recommender. Based on your starter, the system builds a full 6-Pokémon squad:
- Each member fills a different role: DPS, Tank, Speedster, Wall, etc.
- No repeated Type 1s
- One legendary max
- Includes counters to your starter’s weaknesses
To support this, I wrote functions that find counter types and prioritize synergy:

Then, when selecting a team member for a role:

The team selection logic isn’t perfect, but it creates surprisingly thoughtful results using basic stat thresholds, type synergy, and role logic.
Where It Stands
Right now, the recommender is:
- Rule-based (not ML-driven)
- Not truly random — top candidates often repeat
- Doesn’t account for abilities, natures, or movesets
But that’s okay. Because this started with one question about stats, and turned into a strategic playground of data exploration, feature engineering, and just enough tactical thinking to shape meaningful teams.
Final Thoughts
The best data projects often don’t go where you expect. You follow a pattern, find an outlier, chase a different metric, and suddenly you’re building a prototype recommender for a 25-year-old game franchise.
What started as “Let’s compare types” became a much bigger story about how roles, synergy, and decision logic evolve naturally from exploration.
Sometimes it’s not about finding the right answer. It’s about asking the next question.

Leave a comment